# 浏览器
# 1. 多个进程
- 浏览器进程:主要负责界面显示、用户交互、子进程管理,同时提供存储等功能。
- 渲染进程:核心任务是将 HTML、CSS 和 JavaScript 转换为用户可以与之交互的网页,排版引擎Blink和JavaScript引擎V8都是运行在该进程中,默认情况下,Chrome会为每个Tab标签创建一个渲染进程。出于安全考虑,渲染进程都是运行在沙箱模式下。
- GPU进程:UI界面都选择采用GPU来绘制。
- 网络进程:主要负责页面的网络资源加载。
- 插件进程:主要是负责插件的运行,因插件易崩溃,所以需要通过插件进程来隔离。
# 2. 浏览器中的JavaScript执行机制
# 2.1 几个概念
# 大概关系
- 编译 = 词法分析 + 语法解析 + 代码优化 + 代码生成
- 代码 -> 经过编译 -> 执行上下文 + 可执行代码
- 执行上下文 = 变量环境 + 词法环境 + outer + this
- 作用域 = 全局作用域 + 函数作用域 + 块级作用域(大括号包裹的一段代码,可以是函数、判断语句、循环语句、甚至一个空的
{})
# 具体描述
- 执行上下文:JavaScript执行一段代码时的运行环境,比如调用一个函数,就会进入这个函数的执行上下文,确定该函数在执行期间用到的诸如this、变量、对象以及函数等。分类:全局执行上下文、函数执行上下文、eval执行上下文。
- 词法环境:环境记录(保存变量、函数声明和形参)+outer(对外部词法环境的引用),用来存
let&const,在词法环境中,不同的块级作用域是以栈的形式堆叠的。 - 变量环境:环境记录项 + outer,用来存
var,感觉只有一层,因为var是函数作用域,所以在一个函数的执行上下文内,变量环境只有一层,但是词法环境的栈中是有多层的。所以变量环境的outer应该是指向函数的外部,即根据函数来划分界限。 - 变量对象/环境对象:环境中定义的所有变量和函数都保存在这个对象中。(可能这是一个统称)
- 词法环境:环境记录(保存变量、函数声明和形参)+outer(对外部词法环境的引用),用来存
- 作用域:指在程序中定义变量的区域,该位置决定了变量的生命周期。通俗地理解,作用域就是变量与函数的可访问范围,即作用域控制着变量和函数的可见性和生命周期。作用域由词汇环境的链接嵌套组成
- 词法作用域:是由代码中函数声明的位置来决定的,所以词法作用域是静态的作用域,通过它就能够预测代码在执行过程中如何查找标识符。虽然是指向上级,但词法作用域在代码写好的时候就固定了。
- 作用域链:在当前环境中找不到要访问的变量时,根据作用域链索引到外部环境。当前函数的执行上下文中的词法作用域的栈顶->栈底->当前函数的执行上下文中的变量环境->global
- 调用栈:在执行上下文创建好后,JavaScript引擎会将执行上下文压入栈中,通常把这种用来管理执行上下文的栈称为执行上下文栈,又称调用栈。(管理函数调用关系的一种数据结构)
- 闭包:根据词法作用域的规则,内部函数总是可以访问其外部函数中声明的变量,当通过调用一个外部函数返回一个内部函数后,即使该外部函数已经执行结束了,但是内部函数引用外部函数的变量依然保存在内存中,我们就把这些变量的集合称为闭包。
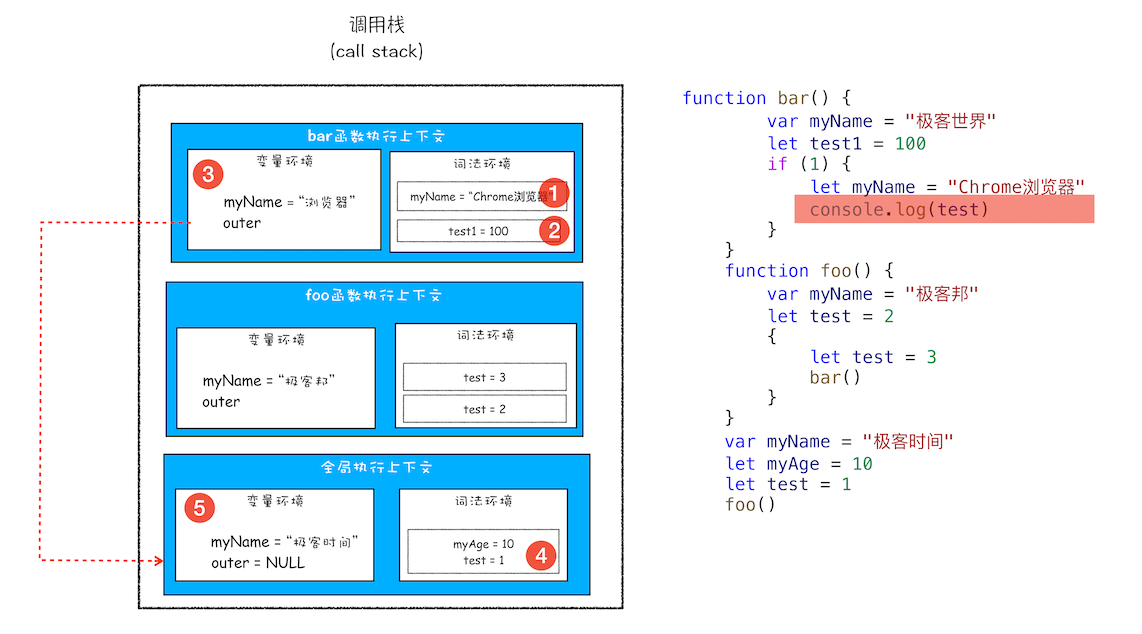
# 2.2 执行流程
- 编译阶段:
- 对JavaScript代码进行变量提升,将代码中的声明部分拆分为声明部分和赋值部分。
- 对于声明的变量,将其在环境对象中创建一个对应的属性,然后使用undefined初始化。
- 如果声明的是函数,则将函数定义存储到变量环境中,并在环境对象中创建一个属性指向堆中函数的位置,进行引用。
- 最后代码被编译为执行上下文+可执行代码。
- 执行阶段:
- 当执行到相关的变量/函数时,JS引擎便在变量环境对象中查找。
# 3. 垃圾回收机制
# 3.1 调用栈的垃圾回收
- 一个叫做ESP的记录当前执行状态的指针,指向调用栈中的栈顶,当栈顶的执行上下文对应的可执行代码执行完毕后,栈顶指针向栈底移动,表示之前的执行上下文已经无效。
- 个人理解:ESP的移动并不意味着之前的执行上下文已经删除,而是在以后(不一定是下次,因为ESP有可能还会往栈底移动,新的执行上下文总是需要从栈顶的位置来入栈)有执行上下文需要入栈的时候,覆盖掉该内存区域。
# 3.2 堆中的垃圾回收
- 当一个变量的数据类型是引用数据类型的时候,他在调用栈中的变量会记录一个地址,这个地址指向该变量在堆中的真实值的位置。
- 在ESP下移,虽然调用栈中数据已经释放,但是堆中仍然保留着该变量的真实值。
# 3.3 分代收集
V8引擎将堆分为两个部分:
- 新生代:存放的是生存时间短的对象,使用副垃圾回收器
- 老生代:存放的是生存时间长的对象,使用主垃圾回收器
# 3.3.1 新生代(副垃圾回收器)/ Scavenge算法
- 将新生代区域平分为两个区域 = 对象区域 + 空闲区域
- 当对象区域快满时,执行垃圾清理算法:
- 标记、清理,把存活的对象复制到空闲区域中,移动的时候还顺带进行了内存整理,消除了内存碎片。
- 复制完成后,对象区域与空闲区域进行角色互换。
# 3.3.2 老生代(主垃圾回收器)/ 标记清除算法
- 最开始,对所有对象进行标记。
- 从一组根元素开始,遍历所有可以到达的活动对象,清除活动对象的标记。
- 剩下来还被标记的元素,就是需要清理的对象。
- 标记整理:所有存活的对象都向一段移动,清理内存碎片。
# 3.3.3 晋升
对象从新生代晋升到老生代,只需要满足下列条件之一:
- 一个对象时第二次从对象区域转移到空闲区域
- 从对象区域向空闲区域复制对象时,如果空闲区域的使用空间超过了25%,则将剩下的对象都移动到老生代。
# 3.4 增量标记算法
- 全停顿:由于 JavaScript 是运行在主线程之上的,一旦执行垃圾回收算法,都需要将正在执行的 JavaScript 脚本暂停下来,待垃圾回收完毕后再恢复脚本执行。
- 对于老生代,全停顿会造成明显的页面卡顿,因此有了增量标记算法:
- 把一个完整的垃圾回收任务拆分为很多小的任务,这些小的任务执行时间比较短,可以穿插在其他的 JavaScript 任务中间执行,这样当执行上述动画效果时,就不会让用户因为垃圾回收任务而感受到页面的卡顿了。
# 3.5 引用计数
- 方法:
- 跟踪记录每个值被引用的次数。
- 将一个引用类型的值,赋给某个变量时,该值的引用次数 +1。反之 -1。
- 当某个值的引用次数变成0的时候,则说明无法再访问这个值了,垃圾收集器下次运行的时候,就会释放这些引用次数为0的值所占用的内存。
- 缺陷:
- 循环引用
- 此外,这里还涉及一个「解除引用」的概念:一旦数据不再有用,最好通过将其值设置为null来释放其引用,让值脱离执行环境,这样在下次垃圾收集器运行的时候,就可以将其回收。
# 3.5 引起内存泄漏的情况
概念:申请的内存空间没有被正确释放,导致后续程序里这块内存被永远占用(不可达)
区别于内存溢出:存储的数据超出了指定空间的大小,这时数据就会越界。
比如在给一个数组赋值的时候,赋值超过了数组的大小,对数组后面的 administrator 元素也赋值了,为 true,拿到了管理员权限。
引起内存泄漏的情况:
- 意外的全局变量
- 被遗忘的计时器或回调函数
- 闭包维持的函数内局部变量
- 未清理的DOM元素引用
# 4. V8引擎如何执行一段JavaScript代码
# 4.1 编译器和解释器
编译器:编译型语言
源代码 -> 词法分析 + 语法分析 -> AST -> 词义分析 -> 中间代码 -> 代码优化 -> 二进制文件 -> 直接执行
解释器:解释型语言
源代码 -> 词法分析 + 语法分析 -> AST -> 词义分析 -> 字节码 -> 解释执行
# 4.2 V8引擎执行JavaScript代码
- 解释器 Ignition,编译器 TurboFan
- 解释器 + 编译器 + 字节码 三者配合的技术 = JIT 即时编译(Just-in-time,JIT)
- Bable原理:ES6代码 -> E6的AST -> 转化 -> ES5的AST -> ES5代码
- ESLint原理:代码 -> AST -> 检查AST来判断代码是否符合规范
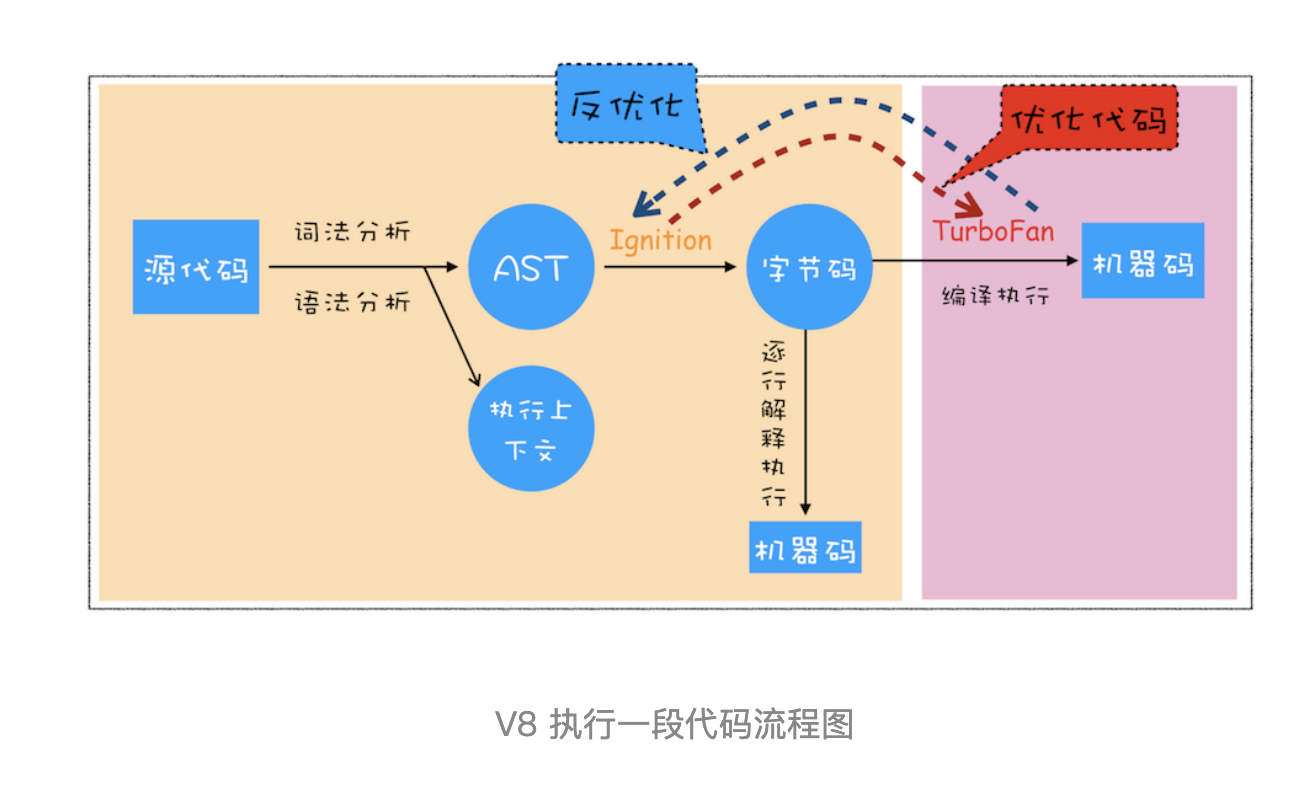
# 4.2.1 生成抽象语法树(AST)和执行上下文:
- 词法分析(分词):将一行行的源码拆解成一个个 token,即语法上不可能再分的、最小的单个字符或字符串。
- 例如,
var myName = "range"就被拆分为4个token - 关键字(keyword) + 标识符(identifier) + 赋值(assignment) + 字符串(literal)
- 例如,
- 语法分析(解析):其作用是将上一步生成的 token 数据,根据语法规则转为 AST。如果源码符合语法规则,这一步就会顺利完成。但如果源码存在语法错误,这一步就会终止,并抛出一个“语法错误”。
# 4.2.2 生成字节码:
解释器 Ignition根据AST生成字节码,并解释执行字节码
字节码就是介于 AST 和机器码之间的一种代码。但是与特定类型的机器码无关,字节码需要通过解释器将其转换为机器码后才能执行。
引入字节码是为了解决机器码会中用大量内存的问题。
# 4.2.3 执行代码
- 第一次执行,解释器 Ignition 逐条解释执行
- 优化:在执行字节码的过程中,监视器(或者叫做 profiler 分析器线程)发现了热点代码(HotSpot),编译器 TurboFan 会把该段热点代码的字节码编译为高效的机器码。
- 再次执行到热点代码时,直接执行编译后的机器码
- 对于循环,其实优化的本质是一种预测,预测循环内的参数长期不变, 如果监视器发现参数变化了,则优化生成的机器码就不能用了,这个时候就需要去优化,继续用解释器执行相关的代码。
# 5. V8引擎的其他特性
# 5.1 代码嵌入
首次优化就是尽可能的提前嵌入更多的代码。代码嵌入就是将使用函数的地方(调用函数的那一行)替换成调用函数的本体。
# 5.2 隐藏类
- JS对象的属性是可变的,也就是说它的地址是可以变化的,因此访问起来效率很低。
- V8在执行时会针对一些“匿名对象”生成隐藏类,从而让它们变成静态类型以提高执行效率,使得对象的属性值(或指向属性的指针)在内存中可以被储存在一个连续的buffer里,且两两之间的偏移量是固定的。
- 隐藏类将对象划分成不同的组,对于组内对象拥有相同的属性名和属性值的情况,将这些组的属性名和对应的偏移位置保存在一个隐藏类中,组内所有对象共享该信息。
- 使用相同的顺序初始化动态属性,这样的话隐藏类就能够复用了,如下所示:
function Point(x, y) {
this.x = x;
this.y = y;
}
var p1 = new Point(1, 2);
p1.a = 5;
p1.b = 6;
var p2 = new Point(3, 4);
p2.a = 7;
p2.b = 8;
// p1和p2会应用相同的隐藏类和类转换。
// 使用Point构造了两个对象p和q,这两个对象具有相同的属性名,V8将它们归为同一个组,也就是隐藏类,这些属性在隐藏类中有相同的偏移值,p和q共享这一信息,进行属性访问时,只需根据隐藏类的偏移值即可。
// 但是如果下面这样:就不会应用相同的隐藏类和类转换。
var p1 = new Point(1, 2);
p1.a = 5;
p1.b = 6;
var p2 = new Point(3, 4);
p2.b = 7;
p2.a = 8;
# 5.3 内联缓存
- V8维护了在最近的方法调用中作为参数传递的对象类型的缓存,使用此信息可以对将来作为参数传递的对象类型做出假设。
- 如果V8能够很好地假设未来将传递给方法的对象的类型,则它可以绕开找出如何访问对象属性的过程,而可以使用先前查找到的对象的隐藏类的存储信息(该信息可以通过偏移量访问属性)。
- 当在某个对象上调用方法的时候,V8引擎会查询对象的隐藏类去决定是否使用偏移量访问对象的属性。如果两次调用了同样的方法到同样的隐藏类。在对相同的隐藏类成功调用同一方法两次之后,V8会省略了隐藏类查找,只是将属性的偏移量添加到对象指针本身。
# 6. 页面线程
# 6.1 页面使用单线程的缺点
- 页面线程所有的执行任务都来自于消息队列(先进先出)
- 如何处理优先级高的任务?同步通知的方式,会影响当前任务的执行效率;如果采用异步方式,又会影响到监控的实时性。
- 如何解决单个任务执行时长过久的问题?
# 6.2 如何处理优先级高的任务(性能 + 实时性 的问题)
宏任务:时间粒度比较大,执行的时间间隔是不能精确控制的,不符合高实时性的要求。
- I / O
- setTimeout
- setInterval
- setImmediate
微任务:一个需要异步执行的函数,执行时机是在主函数执行结束之后、当前宏任务结束之前。
- 微任务的创建,几种方式:
MutationObserver监控某个DOM节点,节点发生变化时,产生DOM变化的微任务(node中不是微任务,但在浏览器中是)
MutationObserver是HTML5中的新API,是个用来监视DOM变动的接口。他能监听一个DOM对象上发生的子节点删除、属性修改、文本内容修改等等。var mo = new MutationObserver(callback) var domTarget = 你想要监听的dom节点 mo.observe(domTarget, { characterData: true //说明监听文本内容的修改。 })
Promise:
Promise.resolve()和Promise.reject()的时候会产生微任务。process.nextTick(在浏览器中不是微任务,在node中是微任务)
- 执行微任务的时间点称为检查点:一般来说,退出全局执行上下文是一个检查点。
- 微任务的创建,几种方式:
消息队列中的任务称为宏任务,每个宏任务中都包含了一个微任务队列,在执行宏任务的过程中,如果有优先级高的任务来,则加入到目前这个宏任务的微任务队列中。
等宏任务中的主要功能都直接完成之后,这时候,渲染引擎并不着急去执行下一个宏任务,而是执行当前宏任务中的微任务,这样也就解决了实时性问题。
# 6.3 如何解决单个任务时长过久的问题?
回调函数。
# 7. 分层和合成机制
# 7.1 引入原因
如果没有采用分层机制,从布局树直接生成目标图片的话,那么每次页面有很小的变化时,都会触发重排或者重绘机制,这种“牵一发而动全身”的绘制策略会严重影响页面的渲染效率。
# 7.2 概念
- 分层:将素材分解为多个图层的操作
- 合成:将这些图层合并到一起的操作
# 7.3 分块
- 分块的概念:合成线程会将每个图层分割为大小固定的图块,然后优先绘制靠近视口的图块,从而加速页面的显示速度。
- 分层:从宏观层面提升了渲染效率
- 分块:从微观层面提升了渲染效率
# 7.4 纹理上传
概念:有时候, 即使只绘制那些优先级最高的图块,也要耗费不少的时间,因为涉及到一个很关键的因素——纹理上传,这是因为从计算机内存上传到 GPU 内存的操作会比较慢。
Chrome应对策略:
在首次合成图块的时候使用一个低分辨率的图片。比如可以是正常分辨率的一半,分辨率减少一半,纹理就减少了四分之三。
在首次显示页面内容的时候,将这个低分辨率的图片显示出来。
然后,合成器继续绘制正常比例的网页内容,当正常比例的网页内容绘制完成后,再替换掉当前显示的低分辨率内容。
这种方式尽管会让用户在开始时看到的是低分辨率的内容,但是也比用户在开始时什么都看不到要好。
# 7.5 利用分层进行优化
.box {
will-change: transform, opacity;
}
- 这段代码就是提前告诉渲染引擎 box 元素将要做几何变换和透明度变换操作,这时候渲染引擎会将该元素单独实现一帧,等这些变换发生时,渲染引擎会通过合成线程直接去处理变换,这些变换并没有涉及到主线程,这样就大大提升了渲染的效率。
- 但是,每当渲染引擎为一个元素准备一个独立层的时候,它占用的内存也会大大增加,因为从层树开始,后续每个阶段都会多一个层结构,这些都需要额外的内存。
# 8.强缓存和协商缓存
# 8.1 基本原理
- 这是两种不同的缓存机制,这两类缓存机制可以同时存在。
- 强制缓存的优先级高于协商缓存,当执行强制缓存时,如若缓存命中,则直接使用缓存数据库数据,不在进行缓存协商。
# 8.2 强缓存
- 机制:当缓存数据库中已有所请求的数据时。客户端直接从缓存数据库中获取数据。当缓存数据库中没有所请求的数据时,客户端的才会从服务端获取数据。
- 通过
expires和cache-control实现
# 8.2.1 expires
- Exprires:值为服务端返回的数据过期时间,GMT格式的标准时间。当再次请求时的请求时间小于返回的此时间,则直接使用缓存数据。
- 但由于服务端时间和客户端时间可能有误差,这也将导致缓存命中的误差,另一方面,Expires是HTTP1.0的产物,故现在大多数使用Cache-Control替代。
# 8.2.2 cache-control
- Cache-Control 出现于 HTTP / 1.1,优先级高于 Expires,表示的是相对时间。
- Cache-Control ,该值是利用max-age判断缓存的生命周期,是以秒为单位,如何在生命周期时间内,则命中缓存。
- 请求指令:
- max-age(单位为s):指定设置缓存最大的有效时间,定义的是时间长短
- s-maxage(单位为s):同max-age,只用于共享缓存(比如CDN缓存)
- no-cache:每次访问资源,浏览器都要向服务器询问,如果文件没变化,服务器只告诉浏览器继续使用缓存(304)。
- no-store :绝对禁止缓存
- 响应指令:
- public :指定响应会被缓存,并且在多用户间共享。
- private :响应只作为私有的缓存,不能在用户间共享。(考虑代理服务器 / 缓存服务器 的情况)
- no-cache:缓存前需要先向服务器验证是否缓存过期
- no-store:禁止缓存
- 为什么cache-control优先级比expires更高?
- Cache-Control是一个时间长度,表示缓存多长时间后过期。
- Expires是一个具体的GMT时间,表示缓存在哪个时间节点之后会过期。
- 在无法确定客户端的时间是否与服务端的时间同步的情况下,Cache-Control相比于expires是更好的选择,所以同时存在时,只有Cache-Control生效。
# 8.3. 协商缓存
- 机制:客户端会先从缓存数据库中获取到一个缓存数据的标识,得到标识后请求服务端验证是否失效(新鲜),如果没有失效服务端会返回304 Not Modified,此时客户端直接从缓存中获取所请求的数据,如果标识失效,服务端会返回更新后的数据。
- 利用
Last-Modified、If-Modified-Since、ETag、If-None-Match
# 8.3.1 Last-modified,If-modified-since
- 这两个东西实质上是一样的,只不过一个是服务器返回给浏览器,一个是浏览器发给服务器。
Last-Modified:服务器返回的数据的一个标识,表示该文件在服务器上的最后修改日期。If-Modified-Since:等于上一次请求的Last-Modified的值,当某个文件过期时(通过 Expires 判断),用于向服务器发送请求的时候,让服务器来比较服务器上对应的文件是否发生了更新。- 浏览器会在request header加上
If-Modified-Since(上次返回的Last-Modified的值),询问服务器在该日期后资源是否有更新,有更新的话就会将新的资源发送回来,无更新的话则返回 304 Not Modified
但是如果在服务器本地打开缓存文件,就会造成 Last-Modified 被修改,但并没有发生实质的变化,所以在 HTTP / 1.1 出现了 ETag
# 8.3.2 Etag,If-none-match
这两个东西实质上也是一样的,只不过一个是服务器返回给浏览器,一个是浏览器发给服务器。
Etag:这个是服务器发给浏览器数据的时候的标识。唯一标识文件内容,文件内容不变tag不变,跟最后修改时间没有关系,ETag可以保证每一个资源是唯一的。If-None-Match:这个是浏览器发给服务器的时候的标识,上一次请求文件时,服务器返回给浏览器的Etag。header会将上次返回的Etag发送给服务器,询问该资源的Etag是否有更新,有变动就会发送新的资源回来。
具体为什么要用ETag,主要出于下面几种情况考虑:
- 不必要的重新下载:一些文件也许会周期性的更改,但是他的内容并不改变(仅仅改变的修改时间),这个时候我们并不希望客户端认为这个文件被修改了,而重新GET;
- If-Modified-Since 时间粒度有限:某些文件修改非常频繁,比如在秒以下的时间内进行修改,(比方说1s内修改了N次),If-Modified-Since能检查到的粒度是s级的,这种修改无法判断(或者说UNIX记录MTIME只能精确到秒);
- 某些服务器不能精确的得到文件的最后修改时间。
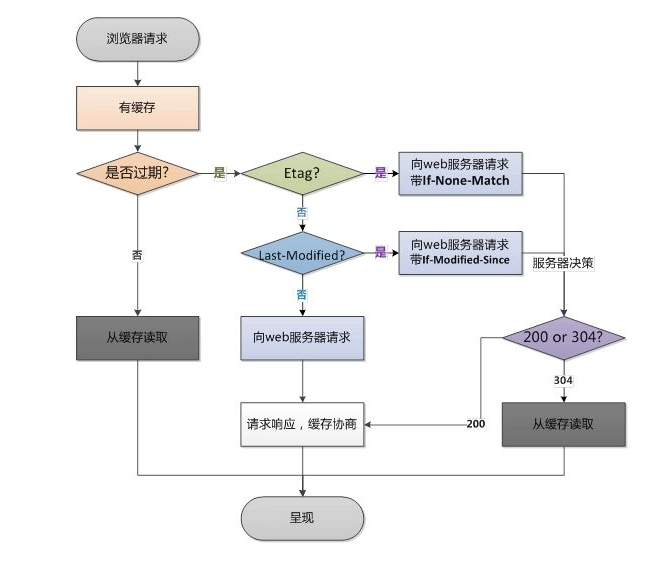
# 8.4 浏览器缓存请求流程
- 浏览器请求某个文件
A - 服务器返回被请求的文件
A,以及该文件的Expires、Cache-Control:max-age=10、Last-Modified、Etag。 - 10秒内,浏览器再次请求文件
A,不再请求服务器,直接使用本地缓存。 - 10秒后,浏览器再次请求文件
A,请求服务器, If-Modified-Since (等于Last-Modified)、 If-None-Match (等于Etag) - 服务器收到浏览器发送过来的数据,比较
If-None-Match和本地的文件A的Etag值,忽略If-Modified-Since的比较。 - 如果
Etag和If-None-Match一致,则说明文件A的内容没变化,服务器告诉浏览器继续使用本地缓存(304)。否则返回本地最新的文件A。
# 9. 浏览器AJAX请求过程
# 9.1 四种线程
一般情况下,浏览器内核有四种线程:
- GUI渲染线程
- JavaScript引擎线程
- 浏览器事件触发线程
- 定时器触发线程
- 异步HTTP请求线程
- 注意,GUI渲染线程与JS引擎线程是互斥的,当JS引擎执行时GUI线程会被挂起(相当于被冻结了),GUI更新会被保存在一个队列中等到JS引擎空闲时立即被执行。
线程之间交互,以事件的方式发生,通过事件回调的方式予以通知。
# 9.2 事件循环
**事件循环:**在浏览器中,js引擎线程会从任务队列中读取事件并执行,这种运行机制称作 Event Loop
- 对于一个AJAX请求,js引擎线程先生成 XMLHttpRequest实例对象,open、send。目前所有的语句都是同步执行
- send之后,浏览器为这个网络请求创建了新的http请求线程,这个线程独立于js线程,两者异步工作(各自继续做各自该做的事情)。
- ajax请求被服务器响应后,浏览器事件触发线程捕获到了ajax的回调事件(onreadystatechange、onload、onerror等),该回调事件并没有马上被执行,而是被添加到任务队列(依次执行)的末尾,等待轮到被执行。(这个时候js还在异步地依次处理任务队列中前面的请求。)
- 在回调事件中,有可能会对DOM进行操作,这个时候浏览器便会挂起js引擎线程,转到GUI渲染线程,进行UI重绘或者回流。当GUI渲染线程的任务完成时,浏览器将会挂起该线程,然后激活js引擎线程。
整个ajax请求过程中,除了GUI线程和js引擎线程是互斥的,其他的线程之间都可以并行执行,因此ajax并没有破坏js的单线程机制。
# 10. 浏览器资源的加载过程
- 第一阶段:Resource Scheduling(资源调度)
- Queueing(排队),可能的原因有三:
- 有更高优先级的请求
- Chrome浏览器中,在同一个域名(Origin)下,已经有6个TCP连接。
- 浏览器正在磁盘缓存中短暂地分配空间
- Queueing(排队),可能的原因有三:
- 第二阶段:Connection Start
- Stalled:因为Queueing中的任何一个原因都会暂停
- Proxy Negotiation:与proxy server协商请求
- 第三阶段:Request / Response
- Request sent
- Waiting(TTFB):Time To First Byte,等待第一个响应的字节,这个时间包括两部分:
- 一个往返延迟(RTT)
- 服务器准备响应所用的时间
- Content Download:浏览器正在接收响应的内容
# 11. DOMContentLoaded和load
- DOMContentLoaded:html被加载和解析完毕,但还未处理:CSS、图片等资源。
- load:所有的资源都已经加载完毕。
- 额外的情况:
- 如果script引入js之前,还有css,由于js要等到css加载完毕(因为js有可能会操作DOM的样式),所以DOMContentLoaded会在css解析完毕之后才触发。
- 但其实load事件之后可能还会有一个
favicon的加载,因为它与页面无关,不会阻塞解析和渲染,优先级较低。